XXXについて
名前はまだない本コンパイラ(以下XXXと仮称)は様々な並列計算アーキテクチャ用に、簡単な記述から演算手順(アセンブラまたはpipeline動作仕様)を生成するためのプログラムである。現時点では、SINGアーキテクチャ用アセンブラ、R700アーキテクチャのGPU用のアセンブラを単一のソース記述から生成する。
SINGアーキテクチャ(GRAPE-DR)とR700アーキテクチャ(AMD/ATiのGPU Radeon 4850/70/90)の計算機は、いずれも多数の演算コアを持つ計算機であり、どちらも自律的には動作できない。このようなタイプの計算機を、ここではメニーコアアクセラレータと呼ぶ。メニーコアアクセラレータは、自律的に動作できないため、他の計算機(ホスト計算機)から制御される。メニーコアアクセラレータは、自分自身が利用するメモリを持っている。通常そのメモリ空間は、ホスト計算機のメモリ空間とは異なるため、ホスト計算機からの明示的なデータ転送が必要である。そのため、メニーコアアクセラレータを利用するには、二種類のプログラムを記述する必要がある。一つはメニーコアアクセラレータで動作するプログラムであり、もう一つはメニーコアアクセラレータを制御するホスト計算機で動作するプログラムである。XXXは、このうち前者のメニーコアアクセラレータで動作するプログラムを生成するためのコンパイラである。ホスト計算機で動作するプログラムを記述するのはユーザーの責任となる。具体的にはホストで動作するプログラムでは、メニーコアアクセラレータの初期化、メニーコアアクセラレータのメモリへのデータ転送、メニーコアアクセラレータでのプログラム実行などが必要であり、これらの記述にはアクセラレータのアーキテクチャに応じたライブラリAPIを利用する必要がある。ただし、異なるメニーコアアクセラレータを統一的に利用するためのAPIについては、XXXの一部として研究開発中であり、また、将来的にはホストプログラムのひな形の自動生成も可能になる予定である。
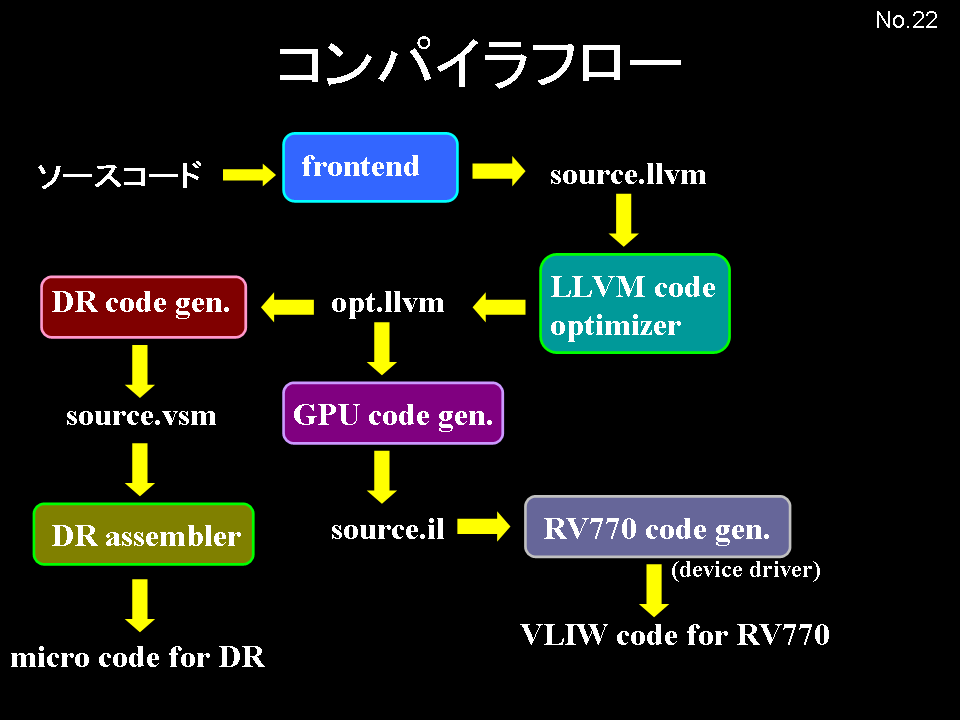
ソース記述から各アーキテクチャのプログラムへの変換は以下の手順を踏む:
- 変数宣言部と演算記述部からなるソースを解析し、演算記述部からは構文木を作成する。
- 構文木を解析し、無限にレジスタがあるとして、演算記述部の2入力1出力の内部アセンブラ記述を生成する。
- 各アーキテクチャに対応するバックエンドが、適宜実レジスタへの割り当てと、命令の変換をおこない、ターゲット用アセンブラを出力する。

現時点でのXXXは、以下のような粒子間相互作用の総和演算をサポートする。
.png)
以下、Xiをi-粒子データ(入力データレジスタ)、Xjをj-粒子データ、fiをf-粒子データ(結果レジスタ)とする。 この粒子間相互作用の総和演算は、以下のような擬似コードで実行することができる。
for i = 0 to N-1
s[i] = 0
for j = 0 to N-1
s[i] += f(x[i], x[j])
この単純な二重ループにおいて、異なるiに対応する演算は独立して実行可能である。よって、外側のループをアンローリングして、以下のようにしても動作は同等である。
for i = 0 to N-1 each 4
s[i] = s[i+1] = s[i+2] = s[i+3] = 0
for j = 0 to N-1
s[i] += f(x[i], x[j])
s[i+1] += f(x[i+1], x[j])
s[i+2] += f(x[i+2], x[j])
s[i+3] += f(x[i+3], x[j])
この擬似コードでは外側のiのループを4段アンローリングしているが、何段になろうとも同様である。XXXでは、アンロールされた異なるiに対応する内側のループを、複数の演算器で並列に実行する。具体的には、XXXでは、メニーコアアクセラレータをプログラム可能な演算機の集合として抽象化している。個々の演算器は、それぞれのローカルなメモリ(実際上はレジスタ)を持ち、さらにこれらの演算器が共有している読み出しメモリがあると考える。また、これらの演算器は常に同一の命令を実行するSIMD動作をする。アンロールされた擬似コードの定義から、これはSIMDプログラムとして実行可能である。GRAPE-DRでは、演算器が512個搭載されているので、単純には外側のループを512段にアンローリングして、別々のiに対するjのループを別々の演算器で実行する。別の言い方をすると、これは外側のループのベクトル化である。通常のベクトル計算機では、ベクトル化されたループはベクトル演算器によりパイプライン処理される。XXXが想定するメニーコアアクセラレータでは、別々の演算器により並列に処理される。
重要なことは、この二重ループの計算においてiの添字を持つ変数とjの添字を持つ変数には、論理的な意味の違いがあることである。具体的には、内側のループが実行される間、iの添字を持つ変数は不変であり、jの添字を持つ変数はイテレーションごとに変化する。よって、内側のループが十分な回数繰り返されるなら、iの添字を持つ変数は何度も繰り返し利用されるため効率がよい。さらに、内側のループが別々の演算器でSIMD的に並列で計算される時、常にすべての演算器で同一のjの添字を持つ変数の読み出しが発生する。これに対応した変数のブロードキャスト機構があれば、jの添字を持つ変数の読み出しに必要なメモリ読み出し速度を演算器の個数に反比例して小さくすることできる。XXXではこの異なるデータアクセスパターンを明示的に指定することで、非常に最適化されたコードを生成可能である。実際、GRAPE-DRはこの種の演算に特化した構造をしており、R700アーキテクチャのGPUはこの種の計算に特化しているわけではないが、実験によるとそのキャッシュ機構のために効率よくこの種の演算を実行できる。
コンパイラとは何か問題
XXXは通常のコンパイラとは異なる思想で動作するため、コンパイラと呼ぶのは厳密には正しくないようだ。XXXが生成するのは、単独で実行可能なプログラムではなく、メニーコアアクセラレータを利用するためのライブラリ相当のプログラムである。XXXの利用者は、この生成されたライブラリを使ってメニーコアアクセラレータを利用するホスト計算機で動作するプログラムを記述する必要がある。
通常、プログラミングにおけるライブラリとは、入出力インターフェイスが決まっていて、なんらかの結果を得るためのルーチンの集合である。例えばDGEMMとは、二つの行列とそのサイズを入力として、行列乗算の結果を得るためのできるルーチンである。入力パラメータである行列の中身やサイズは任意に指定可能であるが、行列乗算という演算自体は変えることができない。他の処理がしたい場合には、他のルーチン(例えば逆行列が必要ならそれ用の)を決められたインターフェイスにもとづいて呼び出す必要がある。ライブラリ内部でどのように計算がおこなわれるかについては、通常利用者は関知できないが、選択をすることは可能である。行列乗算が単純な三重ループで実行されるのか、高度にblock化された最適化アセンブリコードで実行されるのか、アクセラレータ上での計算として実行されるのかは、DGEMMルーチンが現存するどのライブラリと束縛されるかに依存する。
このような通常のライブラリと異なり、XXXは利用者が指定した演算を実行するライブラリを生成する。つまり、これは単純ではあるけれど総和演算向けDSLによるメタプログラミングを行うためのツールであって、このようなものをcompilerと呼称すると、面倒を招く可能性がある。なので、library generatorだとかreconfigurable library、あるいはframework for many-core accelarators(many-core on rails)などと呼ぶほうが正確だろうか?あるいは、こういうMathematicaとかMatlabみたいなのって、第四世代言語っていうんでしたっけ?
XXXは総和演算にのみ対応したframeworkであるが、他のアプリケーションに対応したreconfigurable libraryというのを考えることができる。有用に思えるもので即思いつくのは、meshを利用した各種アルゴリズムに対応したframeworkなど。
そもそもこのようなDSLを作る意義というのは、必要なもの(XXXの場合粒子間相互作用の内容)を定義するだけで、アクセラレータ内部での詳細な演算手段とデータアクセスを隠蔽できることにある。詳細な演算手段とは演算器をどのように使うのがもっとも効率がよいのかということであり、これはメタな演算が同一なら同一の演算パターンが流用できるはずである。GRAPE-DRやR700は、いずれも要素数が4のshort vectorに対する演算をするのが最も効率が良いので、3次元の粒子相互作用の場合にはarray of structureよりもstructure of arrayの方がよい。データアクセスについても同様で、メタな演算が同一であれば、同一のデータアクセスパターンが流用できる。粒子間相互作用の場合に具体的に言うと、演算に必要なデータにはi-粒子とj-粒子という異なるアクセスパターンがあり、これはどのような粒子間相互作用でも同一である。meshを利用したframeworkで必要なデータ移動手段は、隣接meshデータの読み込みであり、それを使って任意のmeshを利用した各種アルゴリズムを記述できるはずである。このような決まり切ったデータアクセスパターンを毎回手動で最適化するのは非生産の極みである。
GRAPE-DRとR700
GRAPE-DRやR700アーキテクチャのGPUは、ベクトル演算器の現代的な実装と言うこともできる。ただし通常のベクトル演算器と異なるのは、ベクトル処理される演算自体が4要素のベクトル演算になっていることである。こういうものは2次元ベクトル演算器と呼ぶのだろうか?
それはさておき、GRAPE-DRとR700は、比較してみると似た構造をしている。具体的には
- アクセラレータとして動作する
- ある程度大きなローカルメモリを持つ
- GRAPE-DRは約256MBでDDR2メモリ
- R700は512MB - 2GBまでいろいろありGDDR3あるいはGDDR5メモリ
- 100個以上の演算器を集積している
- 個々の演算器は単精度・倍精度浮動小数演算や整数演算が可能
- 個々の演算器内部で4 vectorのSIMD演算をおこなう
- GRAPE-DRではレイテンシ隠蔽のために明示的な4 vector演算になる
- R700の演算器は実際には5個のユニットから構成されており、それらはVLIWの命令で制御されるので必ずしも4 vector演算ではない
- 単精度演算と倍精度演算でリソースを共有している
- 全演算器がSIMD的に動作する
- 実際には演算器はグループ化されている。GRAPE-DRでは32個単位で、R700では16個単位である
- 倍精度での積和演算速度がおおよそ200 GFLOPS
- R700の高クロックチップは240 GFLOPS以上になる
という点が似ている。一方で以下のような相違点がある。
- 利用プロセスはGRAPE-DRが90nmに対して、R700は65あるいは45nm
- GRAPE-DRの演算器は非常に単純なのに対して、R700の演算器はVLIWな命令で制御されるある程度複雑なプロセッサ
- R700の演算器は256語のレジスタを持つ。GRAPE-DRの演算器の実効的なレジスタ数は72語
- GRAPE-DRはチップ内部に演算器のグループを接続するreduction networkを持つ
- R700はグループごとのキャッシュ機構を持つ
- R700にはGPUとしての機能も実装されているため、純粋に演算用途だと思うとシリコンの利用効率が悪い
- 結果的に消費電力がGRAPE-DRより大幅に大きい
- ローカルメモリとチップ間のメモリバンド幅が大きく異なる
- GRAPE-DRは4GB/sec程度
- R700は50 - 100 GB/sec
- ローカルメモリの違いも消費電力の差に寄与している
非常におおざっぱに適当なまとめをすると、R700はGRAPE-DRのスーパセットであると言っちゃってもいいはず。一方で、GRAPE-DRのreduction networkが効果的な問題はいろいろとあるし、R700のGPUとしての機能の部分は演算用途にはいらないので、2つのいいとこ取りをしたアーキテクチャを考えるとおもしろい。
Attachments (1)
- SWoPP2009_Nakasato.png (17.7 KB) - added by nakasato 17 years ago.
{kind=link}
Download all attachments as: .zip