| Version 24 (modified by nakasato, 16 years ago) (diff) |
|---|
Matrix Multiply on GPU
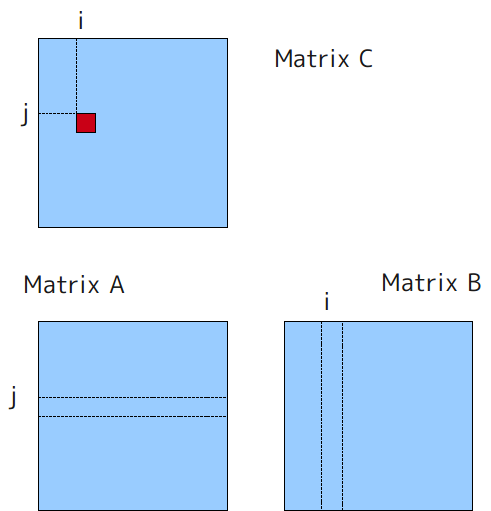
We have implemented single/double precision matrix multiply program for RV770/Cypress. In our implementation, we use two input streams for computing C=AB. One is transposed input matrix A (i.e. column major) and other is input matrix B in normal format (i.e. row major). Output matrix C is also row major. We adopted 8x8 block for single precision and 4x4 for double precision. Here is benchmark result for each case. Note only kernel execution time is measured.
Peformance Summary
| board | Pmax | Nmax | prec | reg. usage | MAD peak |
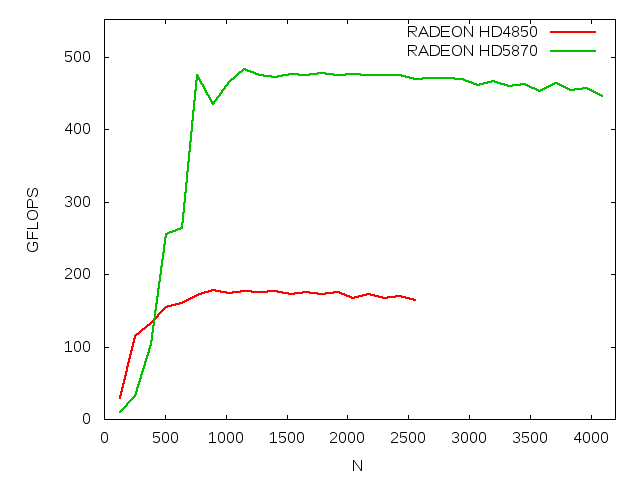
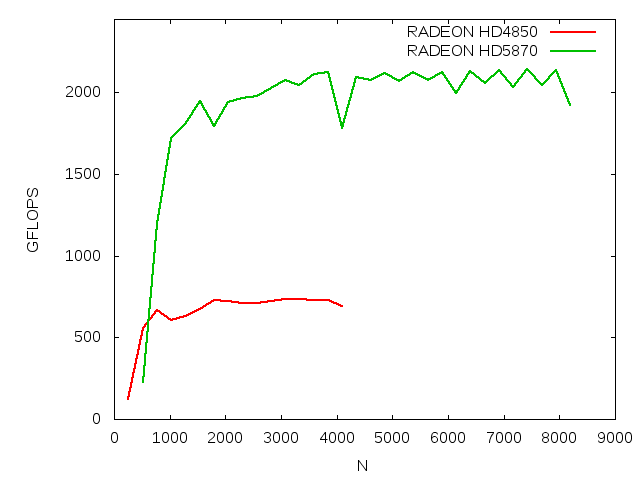
| HD4850 | 736 | 3328 | SP | 25 | 1040 |
| HD5870 | 2140 | 7424 | SP | 25 | 2720 |
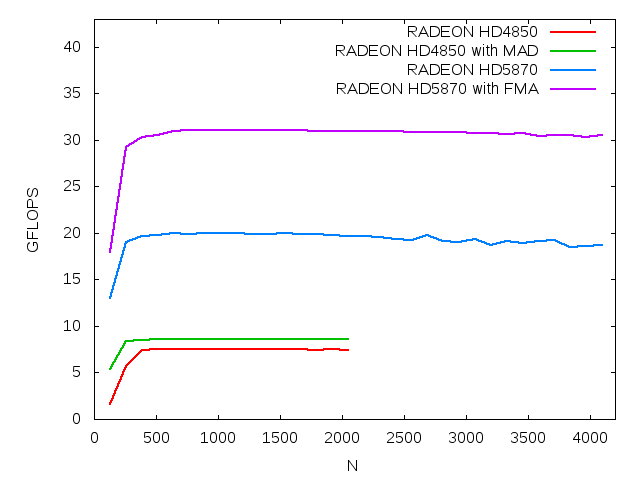
| HD4850 | 177 | 1408 | DP | 19 | 208 |
| HD5870 | 475 | 2048 | DP | 19 | 544 |
Pmax & MAD in GFLOPS
Source code
Will be posted later.
Single precision

Double precision

Useful forum discussions
Discussion on a highly optimized MM kernel
http://forum.beyond3d.com/showthread.php?t=54842
Discussion on MM kernels in OpenCL
http://forums.amd.com/devforum/messageview.cfm?catid=390&threadid=127963
IL code generator in C++
CAL++ http://sourceforge.net/projects/calpp/
Meta-programing works in reality. Impressive work!

Attachments (6)
- MM1.png (12.7 KB) - added by nakasato 16 years ago.
- DMM.png (5.0 KB) - added by nakasato 16 years ago.
- SMM.png (5.3 KB) - added by nakasato 16 years ago.
- DDMM.png (5.2 KB) - added by nakasato 16 years ago.
- dis.txt (19.7 KB) - added by nakasato 16 years ago.
- kernel_single.il (2.8 KB) - added by nakasato 16 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip