Implementation of a Parallel Tree Method on a GPU
by N.Nakasato
Journal of Computational Science, accepted for publication, 2011, March http://dx.doi.org/10.1016/j.jocs.2011.01.006
abstract
The kd-tree is a fundamental tool in computer science. Among other applications, the application of kd-tree search (by the tree method) to the fast evaluation of particle interactions and neighbor search is highly important, since the computational complexity of these problems is reduced from O(N2) for a brute force method to O(N log N) for the tree method, where N is the number of particles. In this paper, we present a parallel implementation of the tree method running on a graphics processing unit (GPU). We present a detailed description of how we have implemented the tree method on a Cypress GPU. An optimization that we found important is localized particle ordering to effectively utilize cache memory. We present a number of test results and performance measurements. Our results show that the execution of the tree traversal in a force calculation on a GPU is practical and efficient.
Preprint
Check arxiv http://arxiv.org/abs/1112.4539
Recent Update (201112)
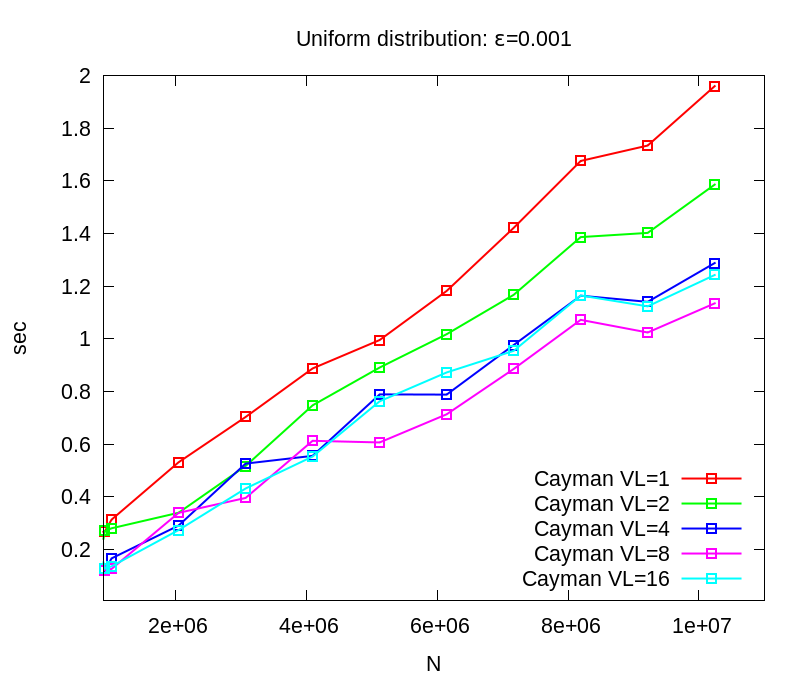
Here is a recent result with AMD APP OpenCL SDK verstion 2.5 on Cayman (Radeon 6970). Thanks for much better cache treatment in AMD SDK, our OpenCL version (see Figure A.11 in our paper) outperforms our IL version. "VL" refers to the explicit vector length in our modified tree walk kernel in OpenCL.

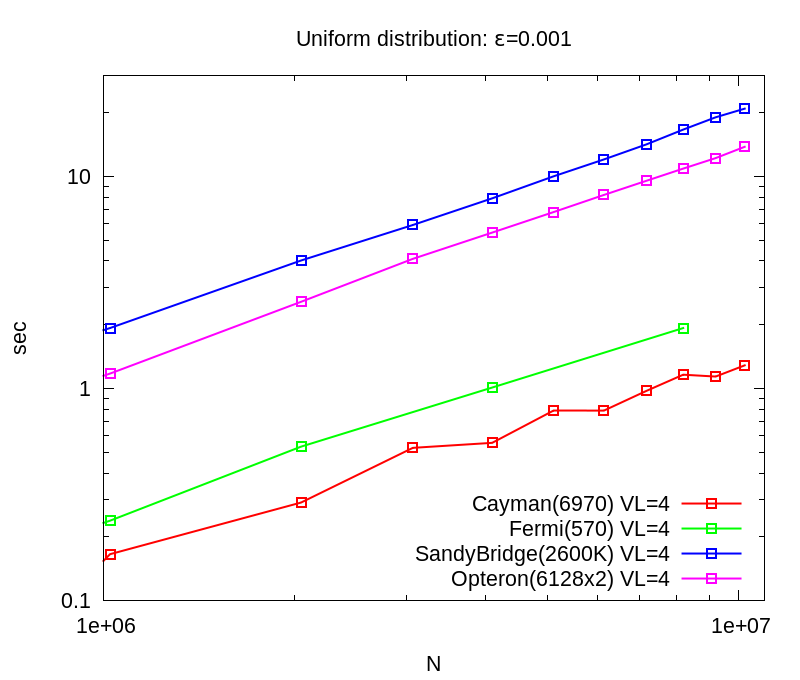
Comparison between different architectures: GPU Cayman & Fermi, CPU Sandy Bridge(4 cores) & Opetron (24 cores)

Attachments (2)
- tree_cayman.png (63.2 KB) - added by nakasato 14 years ago.
- tree_comparison.png (53.1 KB) - added by nakasato 14 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip