Paper
We have just submitted our paper, September 7, 2010. See Fastest_GEMM_implementation_On_Cypress.
Our implementation of MM on GPU
See MatrixMultiply.
Introduction
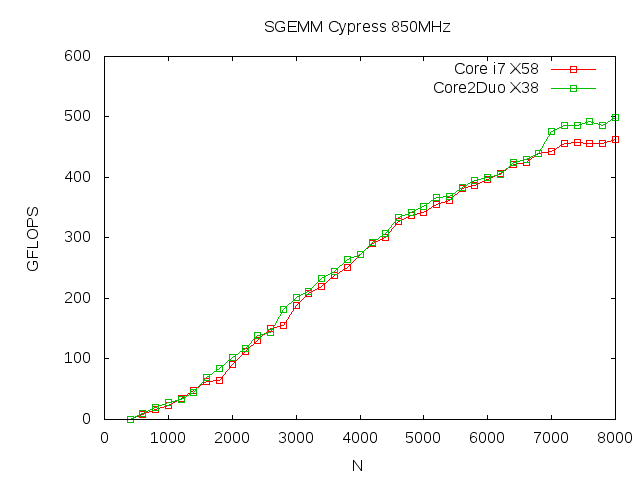
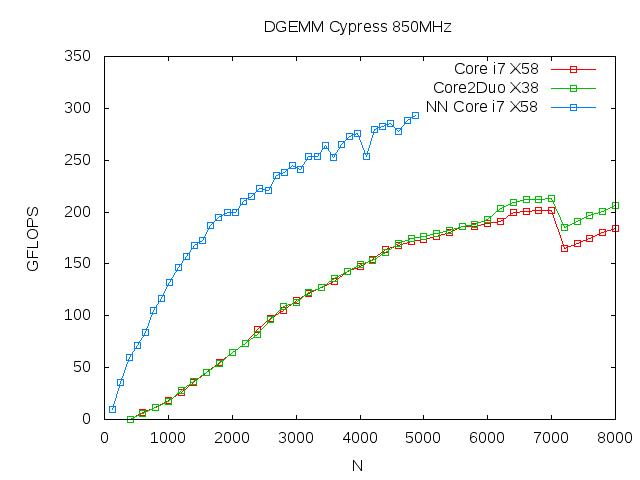
We have tested the ACML-GPU version 1.1. We used Cypress GPU running at 850MHz for our tests. The operating system we adopted is Ubuntu 10.4 LTS. Note we presented two lines for each plot (DP and SP) below. One is the result obtained with X58 chipset and other with X38 chipset. PCI transfer speed of Cypress with X58 chipset shows rather limited performance of roughly 600 MB/sec for GPU to CPU. X38 chips shows reasonable speed of > 6 GB/sec for large data. However, it seems that the transfer speed is not critical for GEMM benchmark.
Update(20100803): We put a preliminary result of our DGEMM routine with alpha = 1 and beta = 1 (the line with "NN"). The performance number presented here includes I/O time between CPU and GPU. It seems we have large room for more aggresive I/O optimizations that should adopt the transposing of input matrix A.
Update(20100808): The previous figure for DGEMM shows wrong results. The correct performance of our DGEMM is slightly slower than the previous data. "NN" is my initial not matrix transpose options. This result is for At B. We are currently working on other options. And will work on scalar constants.
Comment(20100812): With the latest Catalyst 10.7, slow transfer speed for GPU to CPU memory is gone. We have roughly ~ 6 GB/sec for both directions. However, it just represents practical maximum transfer speed with a combination of Cypress and X58 chipset. The actual transfer speed from/to the main memory is rather slow ~ 2.5 GB/sec at most with the pinned memory allocation. This is the problem!
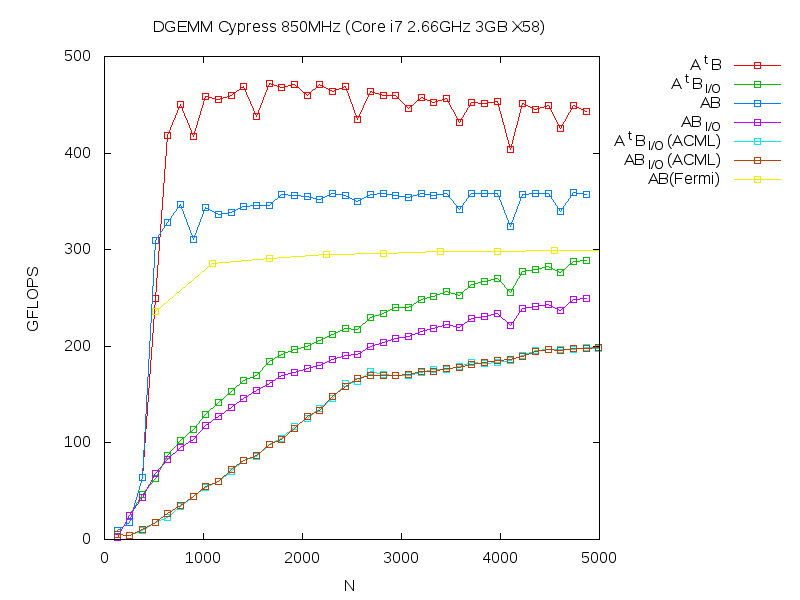
Update(20100819): We have implemented a proper treatment of alpha and beta. In the latest plot, we compare our results with ACML-GPU 1.1 and MAGMA BLAS 0.3 running on Fermi (we plot the numbers in "results_dgemm.txt" that is included in http://icl.cs.utk.edu/projectsfiles/magma/downloads/magmablas_gemm_fermi.tar.gz). We also update ACML-GPU results with consistent benchmark settings. Note the lines without "I/O" show the performance that dose not take into account data transfer time between CPU and GPU.
Results

ACML-GPU 1.1 and our implementation

ACML-GPU 1.1

Attachments (3)
- SGEMM.png (6.8 KB) - added by nakasato 16 years ago.
- DGEMM.png (7.6 KB) - added by nakasato 16 years ago.
- DGEMM_ab.png (12.1 KB) - added by nakasato 16 years ago.
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip